深入拆解Tomcat和Jetty之性能优化 |
您所在的位置:网站首页 › jvm gc原理 › 深入拆解Tomcat和Jetty之性能优化 |
深入拆解Tomcat和Jetty之性能优化
|
本系列文章转自极客时间大佬李号双的专栏《深入拆解Tomcat & Jetty》 链接:https://time.geekbang.org/column/intro/100027701 仅供自己学习,联系我,侵删。 34 | JVM GC原理及调优的基本思路和 Web 应用程序一样,Tomcat 作为一个 Java 程序也跑在 JVM 中,因此如果我们要对 Tomcat 进行调优,需要先了解 JVM 调优的原理。而对于 JVM 调优来说,主要是 JVM 垃圾收集的优化,一般来说是因为有问题才需要优化,所以对于 JVM GC 来说,如果你观察到 Tomcat 进程的 CPU 使用率比较高,并且在 GC 日志中发现 GC 次数比较频繁、GC 停顿时间长,这表明你需要对 GC 进行优化了。 在对 GC 调优的过程中,我们不仅需要知道 GC 的原理,更重要的是要熟练使用各种监控和分析工具,具备 GC 调优的实战能力。CMS 和 G1 是时下使用率比较高的两款垃圾收集器,从 Java 9 开始,采用 G1 作为默认垃圾收集器,而 G1 的目标也是逐步取代 CMS。所以今天我们先来简单回顾一下两种垃圾收集器 CMS 和 G1 的区别,接着通过一个例子帮你提高 GC 调优的实战能力。 CMS vs G1CMS 收集器将 Java 堆分为年轻代(Young)或年老代(Old)。这主要是因为有研究表明,超过 90%的对象在第一次 GC 时就被回收掉,但是少数对象往往会存活较长的时间。 CMS 还将年轻代内存空间分为幸存者空间(Survivor)和伊甸园空间(Eden)。新的对象始终在 Eden 空间上创建。一旦一个对象在一次垃圾收集后还幸存,就会被移动到幸存者空间。当一个对象在多次垃圾收集之后还存活时,它会移动到年老代。这样做的目的是在年轻代和年老代采用不同的收集算法,以达到较高的收集效率,比如在年轻代采用复制 - 整理算法,在年老代采用标记 - 清理算法。因此 CMS 将 Java 堆分成如下区域:
与 CMS 相比,G1 收集器有两大特点: G1 可以并发完成大部分 GC 的工作,这期间不会“Stop-The-World”。 G1 使用非连续空间,这使 G1 能够有效地处理非常大的堆。此外,G1 可以同时收集年轻代和年老代。G1 并没有将 Java 堆分成三个空间(Eden、Survivor 和 Old),而是将堆分成许多(通常是几百个)非常小的区域。这些区域是固定大小的(默认情况下大约为 2MB)。每个区域都分配给一个空间。 G1 收集器的 Java 堆如下图所示:
图上的 U 表示“未分配”区域。G1 将堆拆分成小的区域,一个最大的好处是可以做局部区域的垃圾回收,而不需要每次都回收整个区域比如年轻代和年老代,这样回收的停顿时间会比较短。具体的收集过程是: 将所有存活的对象将从收集的区域复制到未分配的区域,比如收集的区域是 Eden 空间,把 Eden 中的存活对象复制到未分配区域,这个未分配区域就成了 Survivor 空间。理想情况下,如果一个区域全是垃圾(意味着一个存活的对象都没有),则可以直接将该区域声明为“未分配”。 为了优化收集时间,G1 总是优先选择垃圾最多的区域,从而最大限度地减少后续分配和释放堆空间所需的工作量。这也是 G1 收集器名字的由来——Garbage-First。 GC 调优原则GC 是有代价的,因此我们调优的根本原则是每一次 GC 都回收尽可能多的对象,也就是减少无用功。因此我们在做具体调优的时候,针对 CMS 和 G1 两种垃圾收集器,分别有一些相应的策略。 CMS 收集器 对于 CMS 收集器来说,最重要的是合理地设置年轻代和年老代的大小。年轻代太小的话,会导致频繁的 Minor GC,并且很有可能存活期短的对象也不能被回收,GC 的效率就不高。而年老代太小的话,容纳不下从年轻代过来的新对象,会频繁触发单线程 Full GC,导致较长时间的 GC 暂停,影响 Web 应用的响应时间。 G1 收集器 对于 G1 收集器来说,我不推荐直接设置年轻代的大小,这一点跟 CMS 收集器不一样,这是因为 G1 收集器会根据算法动态决定年轻代和年老代的大小。因此对于 G1 收集器,我们需要关心的是 Java 堆的总大小(-Xmx)。 此外 G1 还有一个较关键的参数是-XX:MaxGCPauseMillis = n,这个参数是用来限制最大的 GC 暂停时间,目的是尽量不影响请求处理的响应时间。G1 将根据先前收集的信息以及检测到的垃圾量,估计它可以立即收集的最大区域数量,从而尽量保证 GC 时间不会超出这个限制。因此 G1 相对来说更加“智能”,使用起来更加简单。 内存调优实战下面我通过一个例子实战一下 Java 堆设置得过小,导致频繁的 GC,我们将通过 GC 日志分析工具来观察 GC 活动并定位问题。 首先我们建立一个 Spring Boot 程序,作为我们的调优对象,代码如下: 1234567891011121314151617181920212223@RestControllerpublic class GcTestController { private Queue objCache = new ConcurrentLinkedDeque(); @RequestMapping("/greeting") public Greeting greeting() { Greeting greeting = new Greeting("Hello World!"); if (objCache.size() >= 200000) { objCache.clear(); } else { objCache.add(greeting); } return greeting; }} @Data@AllArgsConstructorclass Greeting { private String message;}上面的代码就是创建了一个对象池,当对象池中的对象数到达 200000 时才清空一次,用来模拟年老代对象。 用下面的命令启动测试程序: 1java -Xmx32m -Xss256k -verbosegc -Xlog:gc*,gc+ref=debug,gc+heap=debug,gc+age=trace:file=gc-%p-%t.log:tags,uptime,time,level:filecount=2,filesize=100m -jar target/demo-0.0.1-SNAPSHOT.jar我给程序设置的堆的大小为 32MB,目的是能让我们看到 Full GC。除此之外,我还打开了 verbosegc 日志,请注意这里我使用的版本是 Java 12,默认的垃圾收集器是 G1。 使用 JMeter 压测工具向程序发送测试请求,访问的路径是/greeting。
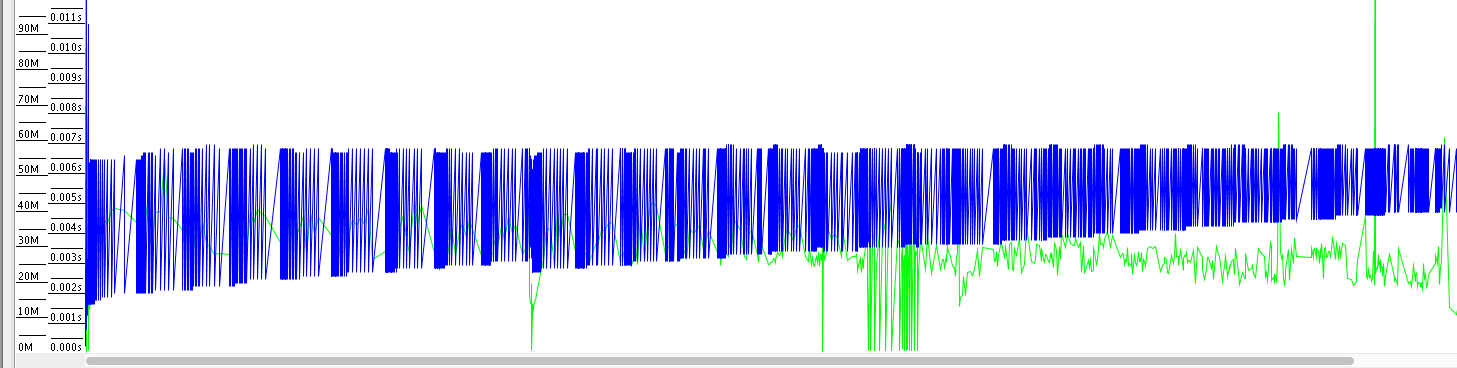
我来解释一下这张图: 图中上部的蓝线表示已使用堆的大小,我们看到它周期的上下震荡,这是我们的对象池要扩展到 200000 才会清空。 图底部的绿线表示年轻代 GC 活动,从图上看到当堆的使用率上去了,会触发频繁的 GC 活动。 图中的竖线表示 Full GC,从图上看到,伴随着 Full GC,蓝线会下降,这说明 Full GC 收集了年老代中的对象。基于上面的分析,我们可以得出一个结论,那就是 Java 堆的大小不够。我来解释一下为什么得出这个结论: GC 活动频繁:年轻代 GC(绿色线)和年老代 GC(黑色线)都比较密集。这说明内存空间不够,也就是 Java 堆的大小不够。 Java 的堆中对象在 GC 之后能够被回收,说明不是内存泄漏。我们通过 GCViewer 还发现累计 GC 暂停时间有 55.57 秒,如下图所示:
因此我们的解决方案是调大 Java 堆的大小,像下面这样: 1java -Xmx2048m -Xss256k -verbosegc -Xlog:gc*,gc+ref=debug,gc+heap=debug,gc+age=trace:file=gc-%p-%t.log:tags,uptime,time,level:filecount=2,filesize=100m -jar target/demo-0.0.1-SNAPSHOT.jar生成的新的 GC log 分析图如下:
你可以看到,没有发生 Full GC,并且年轻代 GC 也没有那么频繁了,并且累计 GC 暂停时间只有 3.05 秒。
今天我们首先回顾了 CMS 和 G1 两种垃圾收集器背后的设计思路以及它们的区别,接着分析了 GC 调优的总体原则。 对于 CMS 来说,我们要合理设置年轻代和年老代的大小。你可能会问该如何确定它们的大小呢?这是一个迭代的过程,可以先采用 JVM 的默认值,然后通过压测分析 GC 日志。 如果我们看年轻代的内存使用率处在高位,导致频繁的 Minor GC,而频繁 GC 的效率又不高,说明对象没那么快能被回收,这时年轻代可以适当调大一点。 如果我们看年老代的内存使用率处在高位,导致频繁的 Full GC,这样分两种情况:如果每次 Full GC 后年老代的内存占用率没有下来,可以怀疑是内存泄漏;如果 Full GC 后年老代的内存占用率下来了,说明不是内存泄漏,我们要考虑调大年老代。 对于 G1 收集器来说,我们可以适当调大 Java 堆,因为 G1 收集器采用了局部区域收集策略,单次垃圾收集的时间可控,可以管理较大的 Java 堆。 35 | 如何监控Tomcat的性能?专栏上一期我们分析了 JVM GC 的基本原理以及监控和分析工具,今天我们接着来聊如何监控 Tomcat 的各种指标,因为只有我们掌握了这些指标和信息,才能对 Tomcat 内部发生的事情一目了然,让我们明白系统的瓶颈在哪里,进而做出调优的决策。 在今天的文章里,我们首先来看看到底都需要监控 Tomcat 哪些关键指标,接着来具体学习如何通过 JConsole 来监控它们。如果系统没有暴露 JMX 接口,我们还可以通过命令行来查看 Tomcat 的性能指标。 Web 应用的响应时间是我们关注的一个重点,最后我们通过一个实战案例,来看看 Web 应用的下游服务响应时间比较长的情况下,Tomcat 的各项指标是什么样子的。 Tomcat 的关键指标Tomcat 的关键指标有吞吐量、响应时间、错误数、线程池、CPU 以及 JVM 内存。 我来简单介绍一下这些指标背后的意义。其中前三个指标是我们最关心的业务指标,Tomcat 作为服务器,就是要能够又快有好地处理请求,因此吞吐量要大、响应时间要短,并且错误数要少。 而后面三个指标是跟系统资源有关的,当某个资源出现瓶颈就会影响前面的业务指标,比如线程池中的线程数量不足会影响吞吐量和响应时间;但是线程数太多会耗费大量 CPU,也会影响吞吐量;当内存不足时会触发频繁地 GC,耗费 CPU,最后也会反映到业务指标上来。 那如何监控这些指标呢?Tomcat 可以通过 JMX 将上述指标暴露出来的。JMX(Java Management Extensions,即 Java 管理扩展)是一个为应用程序、设备、系统等植入监控管理功能的框架。JMX 使用管理 MBean 来监控业务资源,这些 MBean 在 JMX MBean 服务器上注册,代表 JVM 中运行的应用程序或服务。每个 MBean 都有一个属性列表。JMX 客户端可以连接到 MBean Server 来读写 MBean 的属性值。你可以通过下面这张图来理解一下 JMX 的工作原理:
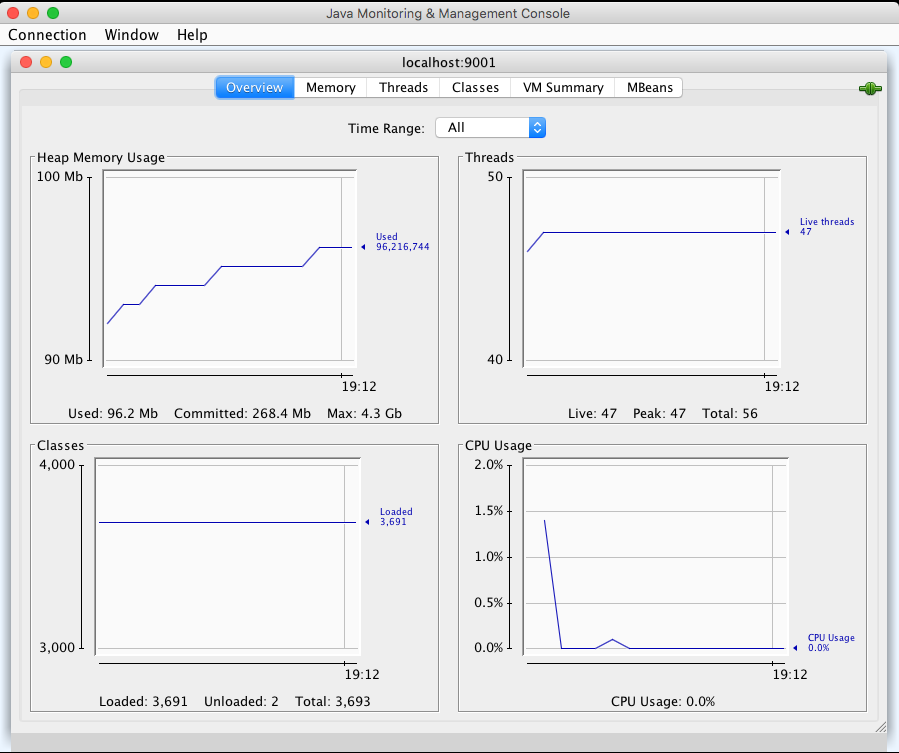
Tomcat 定义了一系列 MBean 来对外暴露系统状态,接下来我们来看看如何通过 JConsole 来监控这些指标。 通过 JConsole 监控 Tomcat首先我们需要开启 JMX 的远程监听端口,具体来说就是设置若干 JVM 参数。我们可以在 Tomcat 的 bin 目录下新建一个名为setenv.sh的文件(或者setenv.bat,根据你的操作系统类型),然后输入下面的内容: 12345export JAVA_OPTS="${JAVA_OPTS} -Dcom.sun.management.jmxremote"export JAVA_OPTS="${JAVA_OPTS} -Dcom.sun.management.jmxremote.port=9001"export JAVA_OPTS="${JAVA_OPTS} -Djava.rmi.server.hostname=x.x.x.x"export JAVA_OPTS="${JAVA_OPTS} -Dcom.sun.management.jmxremote.ssl=false"export JAVA_OPTS="${JAVA_OPTS} -Dcom.sun.management.jmxremote.authenticate=false"重启 Tomcat,这样 JMX 的监听端口 9001 就开启了,接下来通过 JConsole 来连接这个端口。 1jconsole x.x.x.x:9001我们可以看到 JConsole 的主界面:
前面我提到的需要监控的关键指标有吞吐量、响应时间、错误数、线程池、CPU 以及 JVM 内存,接下来我们就来看看怎么在 JConsole 上找到这些指标。 吞吐量、响应时间、错误数 在 MBeans 标签页下选择 GlobalRequestProcessor,这里有 Tomcat 请求处理的统计信息。你会看到 Tomcat 中的各种连接器,展开“http-nio-8080”,你会看到这个连接器上的统计信息,其中 maxTime 表示最长的响应时间,processingTime 表示平均响应时间,requestCount 表示吞吐量,errorCount 就是错误数。
线程池 选择“线程”标签页,可以看到当前 Tomcat 进程中有多少线程,如下图所示:
图的左下方是线程列表,右边是线程的运行栈,这些都是非常有用的信息。如果大量线程阻塞,通过观察线程栈,能看到线程阻塞在哪个函数,有可能是 I/O 等待,或者是死锁。 CPU 在主界面可以找到 CPU 使用率指标,请注意这里的 CPU 使用率指的是 Tomcat 进程占用的 CPU,不是主机总的 CPU 使用率。
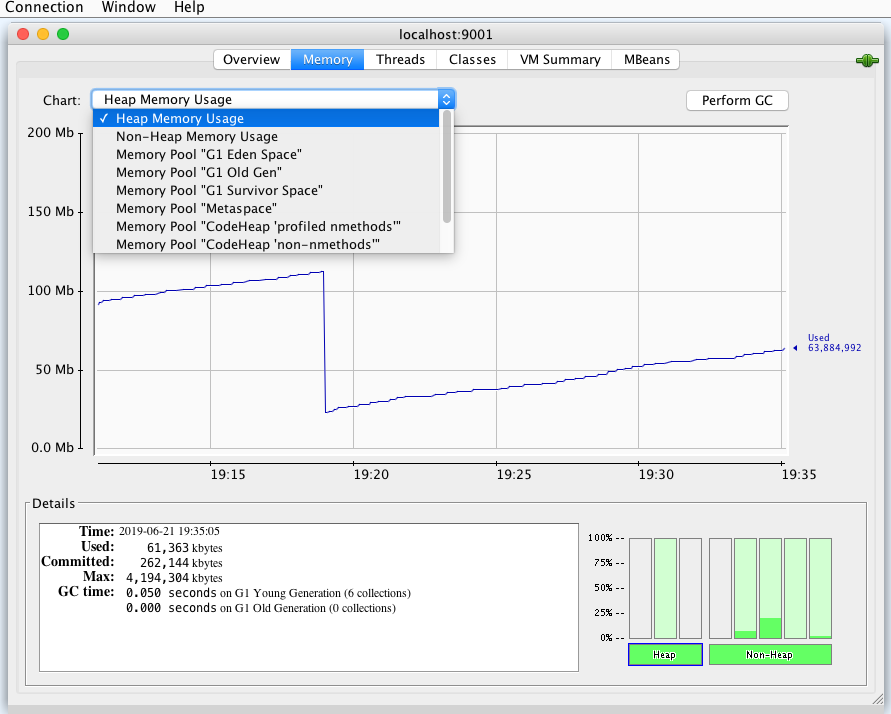
JVM 内存 选择“内存”标签页,你能看到 Tomcat 进程的 JVM 内存使用情况。
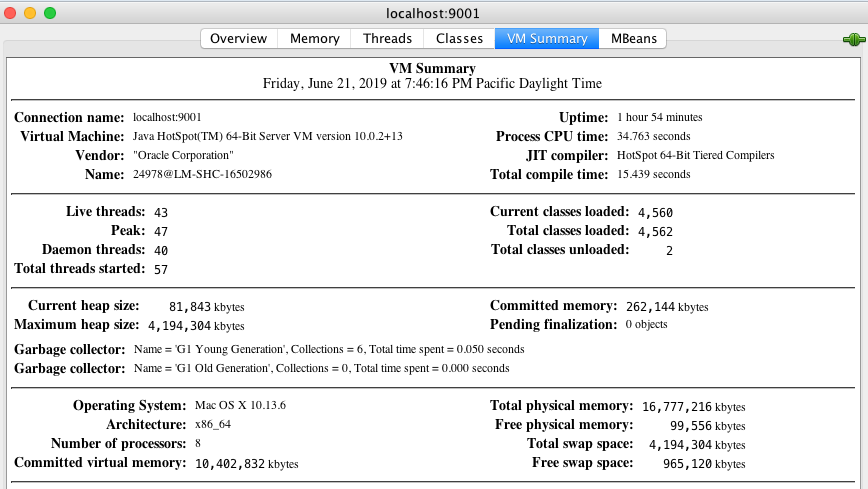
你还可以查看 JVM 各内存区域的使用情况,大的层面分堆区和非堆区。堆区里有分为 Eden、Survivor 和 Old。选择“VM Summary”标签,可以看到虚拟机内的详细信息。
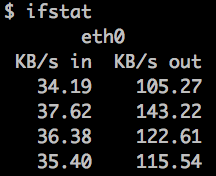
极端情况下如果 Web 应用占用过多 CPU 或者内存,又或者程序中发生了死锁,导致 Web 应用对外没有响应,监控系统上看不到数据,这个时候需要我们登陆到目标机器,通过命令行来查看各种指标。 首先我们通过 ps 命令找到 Tomcat 进程,拿到进程 ID。
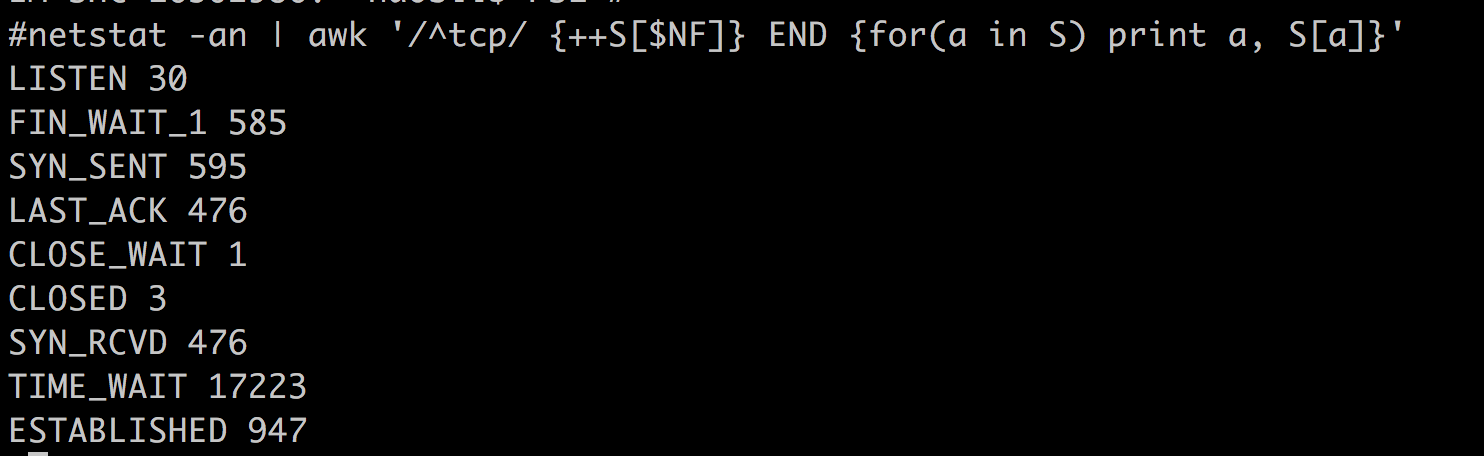
你还可以分别统计处在“已连接”状态和“TIME_WAIT”状态的连接数:
在这个实战案例中,我们会创建一个 Web 应用,根据传入的参数 latency 来休眠相应的秒数,目的是模拟当前的 Web 应用在访问下游服务时遇到的延迟。然后用 JMeter 来压测这个服务,通过 JConsole 来观察 Tomcat 的各项指标,分析和定位问题。 主要的步骤有: 创建一个 Spring Boot 程序,加入下面代码所示的一个 RestController: 1234567891011121314151617@RestControllerpublic class DownStreamLatency { @RequestMapping("/greeting/latency/{seconds}") public Greeting greeting(@PathVariable long seconds) { try { Thread.sleep(seconds * 1000); } catch (InterruptedException e) { e.printStackTrace(); } Greeting greeting = new Greeting("Hello World!"); return greeting; }}从上面的代码我们看到,程序会读取 URL 传过来的 seconds 参数,先休眠相应的秒数,再返回请求。这样做的目的是,客户端压测工具能够控制服务端的延迟。 为了方便观察 Tomcat 的线程数跟延迟之间的关系,还需要加大 Tomcat 的最大线程数,我们可以在application.properties文件中加入这样一行: 1server.tomcat.max-threads=1000server.tomcat.max-threads=1000 启动 JMeter 开始压测,这里我们将压测的线程数设置为 100:
请你注意的是,我们还需要将客户端的 Timeout 设置为 1000 毫秒,这是因为 JMeter 的测试线程在收到响应之前,不会发出下一次请求,这就意味我们没法按照固定的吞吐量向服务端加压。而加了 Timeout 以后,JMeter 会有固定的吞吐量向 Tomcat 发送请求。
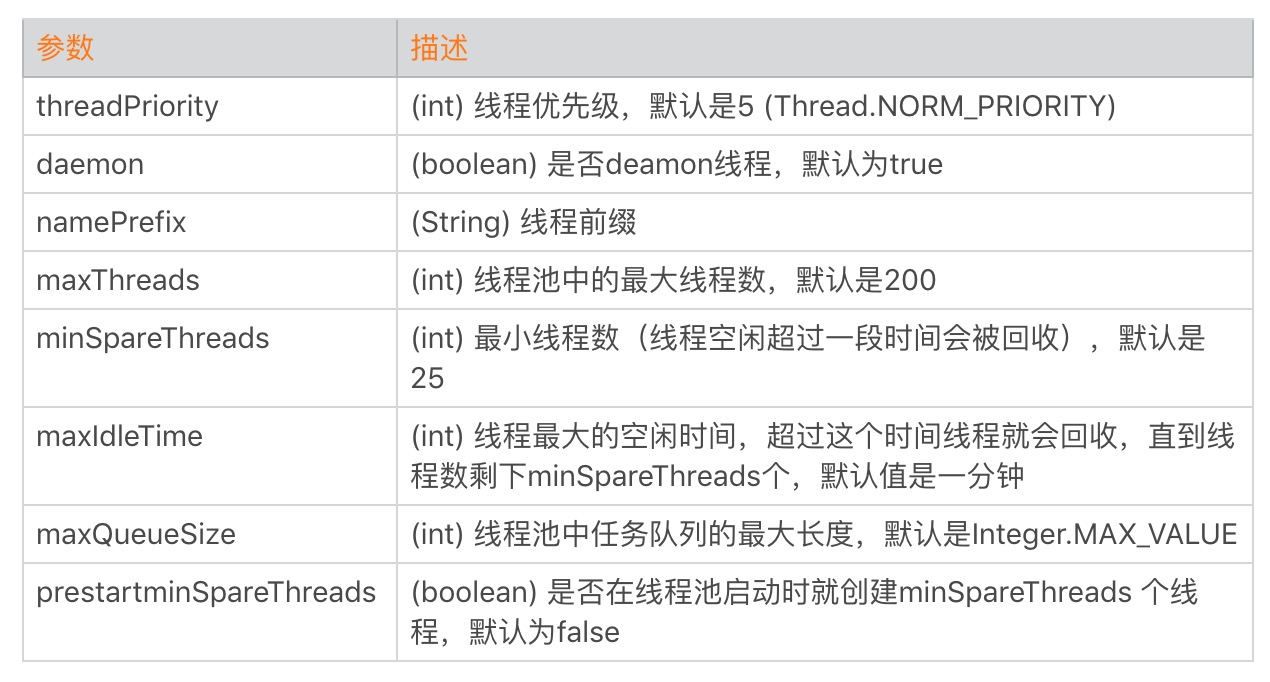
下面我们从线程数、内存和 CPU 这三个指标来分析 Tomcat 的性能问题。 首先看线程数,在第一阶段时间之前,线程数大概是 40,第一阶段压测开始后,线程数增长到 250。为什么是 250 呢?这是因为 JMeter 每秒会发出 100 个请求,每一个请求休眠 2 秒,因此 Tomcat 需要 200 个工作线程来干活;此外 Tomcat 还有一些其他线程用来处理网络通信和后台任务,所以总数是 250 左右。第一阶段压测暂停后,线程数又下降到 40,这是因为线程池会回收空闲线程。第二阶段测试开始后,线程数涨到了 420,这是因为每个请求休眠了 4 秒;同理,我们看到第三阶段测试的线程数是 620。 我们再来看 CPU,在三个阶段的测试中,CPU 的峰值始终比较稳定,这是因为 JMeter 控制了总体的吞吐量,因为服务端用来处理这些请求所需要消耗的 CPU 基本也是一样的。 各测试阶段的内存使用量略有增加,这是因为线程数增加了,创建线程也需要消耗内存。从上面的测试结果我们可以得出一个结论:对于一个 Web 应用来说,下游服务的延迟越大,Tomcat 所需要的线程数越多,但是 CPU 保持稳定。所以如果你在实际工作碰到线程数飙升但是 CPU 没有增加的情况,这个时候你需要怀疑,你的 Web 应用所依赖的下游服务是不是出了问题,响应时间是否变长了。 本期精华今天我们学习了 Tomcat 中的关键的性能指标以及如何监控这些指标:主要有吞吐量、响应时间、错误数、线程池、CPU 以及 JVM 内存。 在实际工作中,我们需要通过观察这些指标来诊断系统遇到的性能问题,找到性能瓶颈。如果我们监控到 CPU 上升,这时我们可以看看吞吐量是不是也上升了,如果是那说明正常;如果不是的话,可以看看 GC 的活动,如果 GC 活动频繁,并且内存居高不下,基本可以断定是内存泄漏。 36 | Tomcat I/O和线程池的并发调优上一期我们谈到了如何监控 Tomcat 的性能指标,在这个基础上,今天我们接着聊如何对 Tomcat 进行调优。 Tomcat 的调优涉及 I/O 模型和线程池调优、JVM 内存调优以及网络优化等,今天我们来聊聊 I/O 模型和线程池调优,由于 Web 应用程序跑在 Tomcat 的工作线程中,因此 Web 应用对请求的处理时间也直接影响 Tomcat 整体的性能,而 Tomcat 和 Web 应用在运行过程中所用到的资源都来自于操作系统,因此调优需要将服务端看作是一个整体来考虑。 所谓的 I/O 调优指的是选择 NIO、NIO.2 还是 APR,而线程池调优指的是给 Tomcat 的线程池设置合适的参数,使得 Tomcat 能够又快又好地处理请求。 I/O 模型的选择I/O 调优实际上是连接器类型的选择,一般情况下默认都是 NIO,在绝大多数情况下都是够用的,除非你的 Web 应用用到了 TLS 加密传输,而且对性能要求极高,这个时候可以考虑 APR,因为 APR 通过 OpenSSL 来处理 TLS 握手和加 / 解密。OpenSSL 本身用 C 语言实现,它还对 TLS 通信做了优化,所以性能比 Java 要高。 那你可能会问那什么时候考虑选择 NIO.2?我的建议是如果你的 Tomcat 跑在 Windows 平台上,并且 HTTP 请求的数据量比较大,可以考虑 NIO.2,这是因为 Windows 从操作系统层面实现了真正意义上的异步 I/O,如果传输的数据量比较大,异步 I/O 的效果就能显现出来。 如果你的 Tomcat 跑在 Linux 平台上,建议使用 NIO,这是因为 Linux 内核没有很完善地支持异步 I/O 模型,因此 JVM 并没有采用原生的 Linux 异步 I/O,而是在应用层面通过 epoll 模拟了异步 I/O 模型,只是 Java NIO 的使用者感觉不到而已。因此可以这样理解,在 Linux 平台上,Java NIO 和 Java NIO.2 底层都是通过 epoll 来实现的,但是 Java NIO 更加简单高效。 线程池调优跟 I/O 模型紧密相关的是线程池,线程池的调优就是设置合理的线程池参数。我们先来看看 Tomcat 线程池中有哪些关键参数:
这里面最核心的就是如何确定 maxThreads 的值,如果这个参数设置小了,Tomcat 会发生线程饥饿,并且请求的处理会在队列中排队等待,导致响应时间变长;如果 maxThreads 参数值过大,同样也会有问题,因为服务器的 CPU 的核数有限,线程数太多会导致线程在 CPU 上来回切换,耗费大量的切换开销。 那 maxThreads 设置成多少才算是合适呢?为了理解清楚这个问题,我们先来看看什么是利特尔法则(Little’s Law)。 利特尔法则 系统中的请求数 = 请求的到达速率 × 每个请求处理时间 其实这个公式很好理解,我举个我们身边的例子:我们去超市购物结账需要排队,但是你是如何估算一个队列有多长呢?队列中如果每个人都买很多东西,那么结账的时间就越长,队列也会越长;同理,短时间一下有很多人来收银台结账,队列也会变长。因此队列的长度等于新人加入队列的频率乘以平均每个人处理的时间。 计算出了队列的长度,那么我们就创建相应数量的线程来处理请求,这样既能以最快的速度处理完所有请求,同时又没有额外的线程资源闲置和浪费。 假设一个单核服务器在接收请求: 如果每秒 10 个请求到达,平均处理一个请求需要 1 秒,那么服务器任何时候都有 10 个请求在处理,即需要 10 个线程。 如果每秒 10 个请求到达,平均处理一个请求需要 2 秒,那么服务器在每个时刻都有 20 个请求在处理,因此需要 20 个线程。 如果每秒 10000 个请求到达,平均处理一个请求需要 1 秒,那么服务器在每个时刻都有 10000 个请求在处理,因此需要 10000 个线程。因此可以总结出一个公式: 线程池大小 = 每秒请求数 × 平均请求处理时间 这是理想的情况,也就是说线程一直在忙着干活,没有被阻塞在 I/O 等待上。实际上任务在执行中,线程不可避免会发生阻塞,比如阻塞在 I/O 等待上,等待数据库或者下游服务的数据返回,虽然通过非阻塞 I/O 模型可以减少线程的等待,但是数据在用户空间和内核空间拷贝过程中,线程还是阻塞的。线程一阻塞就会让出 CPU,线程闲置下来,就好像工作人员不可能 24 小时不间断地处理客户的请求,解决办法就是增加工作人员的数量,一个人去休息另一个人再顶上。对应到线程池就是增加线程数量,因此 I/O 密集型应用需要设置更多的线程。 线程 I/O 时间与 CPU 时间 至此我们又得到一个线程池个数的计算公式,假设服务器是单核的: 线程池大小 = (线程 I/O 阻塞时间 + 线程 CPU 时间 )/ 线程 CPU 时间 其中:线程 I/O 阻塞时间 + 线程 CPU 时间 = 平均请求处理时间 对比一下两个公式,你会发现,平均请求处理时间在两个公式里都出现了,这说明请求时间越长,需要更多的线程是毫无疑问的。 不同的是第一个公式是用每秒请求数来乘以请求处理时间;而第二个公式用请求处理时间来除以线程 CPU 时间,请注意 CPU 时间是小于请求处理时间的。 虽然这两个公式是从不同的角度来看待问题的,但都是理想情况,都有一定的前提条件。 请求处理时间越长,需要的线程数越多,但前提是 CPU 核数要足够,如果一个 CPU 来支撑 10000 TPS 并发,创建 10000 个线程,显然不合理,会造成大量线程上下文切换。 请求处理过程中,I/O 等待时间越长,需要的线程数越多,前提是 CUP 时间和 I/O 时间的比率要计算的足够准确。 请求进来的速率越快,需要的线程数越多,前提是 CPU 核数也要跟上。 实际场景下如何确定线程数那么在实际情况下,线程池的个数如何确定呢?这是一个迭代的过程,先用上面两个公式大概算出理想的线程数,再反复压测调整,从而达到最优。 一般来说,如果系统的 TPS 要求足够大,用第一个公式算出来的线程数往往会比公式二算出来的要大。我建议选取这两个值中间更靠近公式二的值。也就是先设置一个较小的线程数,然后进行压测,当达到系统极限时(错误数增加,或者响应时间大幅增加),再逐步加大线程数,当增加到某个值,再增加线程数也无济于事,甚至 TPS 反而下降,那这个值可以认为是最佳线程数。 线程池中其他的参数,最好就用默认值,能不改就不改,除非在压测的过程发现了瓶颈。如果发现了问题就需要调整,比如 maxQueueSize,如果大量任务来不及处理都堆积在 maxQueueSize 中,会导致内存耗尽,这个时候就需要给 maxQueueSize 设一个限制。当然,这是一个比较极端的情况了。 再比如 minSpareThreads 参数,默认是 25 个线程,如果你发现系统在闲的时候用不到 25 个线程,就可以调小一点;如果系统在大部分时间都比较忙,线程池中的线程总是远远多于 25 个,这个时候你就可以把这个参数调大一点,因为这样线程池就不需要反复地创建和销毁线程了。 本期精华今天我们学习了 I/O 调优,也就是如何选择连接器的类型,以及在选择过程中有哪些需要注意的地方。 后面还聊到 Tomcat 线程池的各种参数,其中最重要的参数是最大线程数 maxThreads。理论上我们可以通过利特尔法则或者 CPU 时间与 I/O 时间的比率,计算出一个理想值,这个值只具有指导意义,因为它受到各种资源的限制,实际场景中,我们需要在理想值的基础上进行压测,来获得最佳线程数。 37 | Tomcat内存溢出的原因分析及调优作为 Java 程序员,我们几乎都会碰到 java.lang.OutOfMemoryError 异常,但是你知道有哪些原因可能导致 JVM 抛出 OutOfMemoryError 异常吗? JVM 在抛出 java.lang.OutOfMemoryError 时,除了会打印出一行描述信息,还会打印堆栈跟踪,因此我们可以通过这些信息来找到导致异常的原因。在寻找原因前,我们先来看看有哪些因素会导致 OutOfMemoryError,其中内存泄漏是导致 OutOfMemoryError 的一个比较常见的原因,最后我们通过一个实战案例来定位内存泄漏。 内存溢出场景及方案java.lang.OutOfMemoryError: Java heap space JVM 无法在堆中分配对象时,会抛出这个异常,导致这个异常的原因可能有三种: \1. 内存泄漏。Java 应用程序一直持有 Java 对象的引用,导致对象无法被 GC 回收,比如对象池和内存池中的对象无法被 GC 回收。\2. 配置问题。有可能是我们通过 JVM 参数指定的堆大小(或者未指定的默认大小),对于应用程序来说是不够的。解决办法是通过 JVM 参数加大堆的大小。3.finalize 方法的过度使用。如果我们想在 Java 类实例被 GC 之前执行一些逻辑,比如清理对象持有的资源,可以在 Java 类中定义 finalize 方法,这样 JVM GC 不会立即回收这些对象实例,而是将对象实例添加到一个叫“java.lang.ref.Finalizer.ReferenceQueue”的队列中,执行对象的 finalize 方法,之后才会回收这些对象。Finalizer 线程会和主线程竞争 CPU 资源,但由于优先级低,所以处理速度跟不上主线程创建对象的速度,因此 ReferenceQueue 队列中的对象就越来越多,最终会抛出 OutOfMemoryError。解决办法是尽量不要给 Java 类定义 finalize 方法。 java.lang.OutOfMemoryError: GC overhead limit exceeded 出现这种 OutOfMemoryError 的原因是,垃圾收集器一直在运行,但是 GC 效率很低,比如 Java 进程花费超过 98%的 CPU 时间来进行一次 GC,但是回收的内存少于 2%的 JVM 堆,并且连续 5 次 GC 都是这种情况,就会抛出 OutOfMemoryError。 解决办法是查看 GC 日志或者生成 Heap Dump,确认一下是不是内存泄漏,如果不是内存泄漏可以考虑增加 Java 堆的大小。当然你还可以通过参数配置来告诉 JVM 无论如何也不要抛出这个异常,方法是配置-XX:-UseGCOverheadLimit,但是我并不推荐这么做,因为这只是延迟了 OutOfMemoryError 的出现。 java.lang.OutOfMemoryError: Requested array size exceeds VM limit 从错误消息我们也能猜到,抛出这种异常的原因是“请求的数组大小超过 JVM 限制”,应用程序尝试分配一个超大的数组。比如应用程序尝试分配 512MB 的数组,但最大堆大小为 256MB,则将抛出 OutOfMemoryError,并且请求的数组大小超过 VM 限制。 通常这也是一个配置问题(JVM 堆太小),或者是应用程序的一个 Bug,比如程序错误地计算了数组的大小,导致尝试创建一个大小为 1GB 的数组。 java.lang.OutOfMemoryError: MetaSpace 如果 JVM 的元空间用尽,则会抛出这个异常。我们知道 JVM 元空间的内存在本地内存中分配,但是它的大小受参数 MaxMetaSpaceSize 的限制。当元空间大小超过 MaxMetaSpaceSize 时,JVM 将抛出带有 MetaSpace 字样的 OutOfMemoryError。解决办法是加大 MaxMetaSpaceSize 参数的值。 java.lang.OutOfMemoryError: Request size bytes for reason. Out of swap space 当本地堆内存分配失败或者本地内存快要耗尽时,Java HotSpot VM 代码会抛出这个异常,VM 会触发“致命错误处理机制”,它会生成“致命错误”日志文件,其中包含崩溃时线程、进程和操作系统的有用信息。如果碰到此类型的 OutOfMemoryError,你需要根据 JVM 抛出的错误信息来进行诊断;或者使用操作系统提供的 DTrace 工具来跟踪系统调用,看看是什么样的程序代码在不断地分配本地内存。 java.lang.OutOfMemoryError: Unable to create native threads 抛出这个异常的过程大概是这样的: 1.Java 程序向 JVM 请求创建一个新的 Java 线程。2.JVM 本地代码(Native Code)代理该请求,通过调用操作系统 API 去创建一个操作系统级别的线程 Native Thread。\3. 操作系统尝试创建一个新的 Native Thread,需要同时分配一些内存给该线程,每一个 Native Thread 都有一个线程栈,线程栈的大小由 JVM 参数-Xss决定。\4. 由于各种原因,操作系统创建新的线程可能会失败,下面会详细谈到。5.JVM 抛出“java.lang.OutOfMemoryError: Unable to create new native thread”错误。 因此关键在于第四步线程创建失败,JVM 就会抛出 OutOfMemoryError,那具体有哪些因素会导致线程创建失败呢? \1. 内存大小限制:我前面提到,Java 创建一个线程需要消耗一定的栈空间,并通过-Xss参数指定。请你注意的是栈空间如果过小,可能会导致 StackOverflowError,尤其是在递归调用的情况下;但是栈空间过大会占用过多内存,而对于一个 32 位 Java 应用来说,用户进程空间是 4GB,内核占用 1GB,那么用户空间就剩下 3GB,因此它能创建的线程数大致可以通过这个公式算出来: 1Max memory(3GB) = [-Xmx] + [-XX:MaxMetaSpaceSize] + number_of_threads * [-Xss]不过对于 64 位的应用,由于虚拟进程空间近乎无限大,因此不会因为线程栈过大而耗尽虚拟地址空间。但是请你注意,64 位的 Java 进程能分配的最大内存数仍然受物理内存大小的限制。 2.ulimit 限制,在 Linux 下执行ulimit -a,你会看到 ulimit 对各种资源的限制。
其中的“max user processes”就是一个进程能创建的最大线程数,我们可以修改这个参数:
3.参数sys.kernel.threads-max限制。这个参数限制操作系统全局的线程数,通过下面的命令可以查看它的值。
这表明当前系统能创建的总的线程是 63752。当然我们调整这个参数,具体办法是: 在/etc/sysctl.conf配置文件中,加入sys.kernel.threads-max = 999999。 4.参数sys.kernel.pid_max限制,这个参数表示系统全局的 PID 号数值的限制,每一个线程都有 ID,ID 的值超过这个数,线程就会创建失败。跟sys.kernel.threads-max参数一样,我们也可以将sys.kernel.pid_max调大,方法是在/etc/sysctl.conf配置文件中,加入sys.kernel.pid_max = 999999。 对于线程创建失败的 OutOfMemoryError,除了调整各种参数,我们还需要从程序本身找找原因,看看是否真的需要这么多线程,有可能是程序的 Bug 导致创建过多的线程。 内存泄漏定位实战我们先创建一个 Web 应用,不断地 new 新对象放到一个 List 中,来模拟 Web 应用中的内存泄漏。然后通过各种工具来观察 GC 的行为,最后通过生成 Heap Dump 来找到泄漏点。 内存泄漏模拟程序比较简单,创建一个 Spring Boot 应用,定义如下所示的类: 12345678910111213141516171819import org.springframework.scheduling.annotation.Scheduled;import org.springframework.stereotype.Component; import java.util.LinkedList;import java.util.List; @Componentpublic class MemLeaker { private List objs = new LinkedList(); @Scheduled(fixedRate = 1000) public void run() { for (int i = 0; i < 50000; i++) { objs.add(new Object()); } }}这个程序做的事情就是每隔 1 秒向一个 List 中添加 50000 个对象。接下来运行并通过工具观察它的 GC 行为: 运行程序并打开 verbosegc,将 GC 的日志输出到 gc.log 文件中。 1java -verbose:gc -Xloggc:gc.log -XX:+PrintGCDetails -jar mem-0.0.1-SNAPSHOT.jar 使用jstat命令观察 GC 的过程: 1jstat -gc 94223 2000 100094223 是程序的进程 ID,2000 表示每隔 2 秒执行一次,1000 表示持续执行 1000 次。下面是命令的输出:
其中每一列的含义是: S0C:第一个 Survivor 区总的大小; S1C:第二个 Survivor 区总的大小; S0U:第一个 Survivor 区已使用内存的大小; S1U:第二个 Survivor 区已使用内存的大小。后面的列相信从名字你也能猜出是什么意思了,其中 E 代表 Eden,O 代表 Old,M 代表 Metadata;YGC 表示 Minor GC 的总时间,YGCT 表示 Minor GC 的次数;FGC 表示 Full GC。 通过这个工具,你能大概看到各个内存区域的大小、已经 GC 的次数和所花的时间。verbosegc 参数对程序的影响比较小,因此很适合在生产环境现场使用。 通过 GCViewer 工具查看 GC 日志,用 GCViewer 打开第一步产生的 gc.log,会看到这样的图:
图中红色的线表示年老代占用的内存,你会看到它一直在增加,而黑色的竖线表示一次 Full GC。你可以看到后期 JVM 在频繁地 Full GC,但是年老代的内存并没有降下来,这是典型的内存泄漏的特征。 除了内存泄漏,我们还可以通过 GCViewer 来观察 Minor GC 和 Full GC 的频次,已及每次的内存回收量。 为了找到内存泄漏点,我们通过 jmap 工具生成 Heap Dump: 1jmap -dump:live,format=b,file=94223.bin 94223 用 Eclipse Memory Analyzer 打开 Dump 文件,通过内存泄漏分析,得到这样一个分析报告:
从报告中可以看到,JVM 内存中有一个长度为 4000 万的 List,至此我们也就找到了泄漏点。 本期精华今天我讲解了常见的 OutOfMemoryError 的场景以及解决办法,我们在实际工作中要根据具体的错误信息去分析背后的原因,尤其是 Java 堆内存不够时,需要生成 Heap Dump 来分析,看是不是内存泄漏;排除内存泄漏之后,我们再调整各种 JVM 参数,否则根本的问题原因没有解决的话,调整 JVM 参数也无济于事。 38 | Tomcat拒绝连接原因分析及网络优化专栏上一期我们分析各种 JVM OutOfMemory 错误的原因和解决办法,今天我们来看看网络通信中可能会碰到的各种错误。网络通信方面的错误和异常也是我们在实际工作中经常碰到的,需要理解异常背后的原理,才能更快更精准地定位问题,从而找到解决办法。 下面我会先讲讲 Java Socket 网络编程常见的异常有哪些,然后通过一个实验来重现其中的 Connection reset 异常,并且通过配置 Tomcat 的参数来解决这个问题。 常见异常java.net.SocketTimeoutException 指超时错误。超时分为连接超时和读取超时,连接超时是指在调用 Socket.connect 方法的时候超时,而读取超时是调用 Socket.read 方法时超时。请你注意的是,连接超时往往是由于网络不稳定造成的,但是读取超时不一定是网络延迟造成的,很有可能是下游服务的响应时间过长。 java.net.BindException: Address already in use: JVM_Bind 指端口被占用。当服务器端调用 new ServerSocket(port) 或者 Socket.bind 函数时,如果端口已经被占用,就会抛出这个异常。我们可以用netstat –an命令来查看端口被谁占用了,换一个没有被占用的端口就能解决。 java.net.ConnectException: Connection refused: connect 指连接被拒绝。当客户端调用 new Socket(ip, port) 或者 Socket.connect 函数时,可能会抛出这个异常。原因是指定 IP 地址的机器没有找到;或者是机器存在,但这个机器上没有开启指定的监听端口。 解决办法是从客户端机器 ping 一下服务端 IP,假如 ping 不通,可以看看 IP 是不是写错了;假如能 ping 通,需要确认服务端的服务是不是崩溃了。 java.net.SocketException: Socket is closed 指连接已关闭。出现这个异常的原因是通信的一方主动关闭了 Socket 连接(调用了 Socket 的 close 方法),接着又对 Socket 连接进行了读写操作,这时操作系统会报“Socket 连接已关闭”的错误。 java.net.SocketException: Connection reset/Connect reset by peer: Socket write error 指连接被重置。这里有两种情况,分别对应两种错误:第一种情况是通信的一方已经将 Socket 关闭,可能是主动关闭或者是因为异常退出,这时如果通信的另一方还在写数据,就会触发这个异常(Connect reset by peer);如果对方还在尝试从 TCP 连接中读数据,则会抛出 Connection reset 异常。 为了避免这些异常发生,在编写网络通信程序时要确保: 程序退出前要主动关闭所有的网络连接。 检测通信的另一方的关闭连接操作,当发现另一方关闭连接后自己也要关闭该连接。java.net.SocketException: Broken pipe 指通信管道已坏。发生这个异常的场景是,通信的一方在收到“Connect reset by peer: Socket write error”后,如果再继续写数据则会抛出 Broken pipe 异常,解决方法同上。 java.net.SocketException: Too many open files 指进程打开文件句柄数超过限制。当并发用户数比较大时,服务器可能会报这个异常。这是因为每创建一个 Socket 连接就需要一个文件句柄,此外服务端程序在处理请求时可能也需要打开一些文件。 你可以通过lsof -p pid命令查看进程打开了哪些文件,是不是有资源泄露,也就是说进程打开的这些文件本应该被关闭,但由于程序的 Bug 而没有被关闭。 如果没有资源泄露,可以通过设置增加最大文件句柄数。具体方法是通过ulimit -a来查看系统目前资源限制,通过ulimit -n 10240修改最大文件数。 Tomcat 网络参数接下来我们看看 Tomcat 两个比较关键的参数:maxConnections 和 acceptCount。在解释这个参数之前,先简单回顾下 TCP 连接的建立过程:客户端向服务端发送 SYN 包,服务端回复 SYN+ACK,同时将这个处于 SYN_RECV 状态的连接保存到半连接队列。客户端返回 ACK 包完成三次握手,服务端将 ESTABLISHED 状态的连接移入accept 队列,等待应用程序(Tomcat)调用 accept 方法将连接取走。这里涉及两个队列: 半连接队列:保存 SYN_RECV 状态的连接。队列长度由net.ipv4.tcp_max_syn_backlog设置。 accept 队列:保存 ESTABLISHED 状态的连接。队列长度为min(net.core.somaxconn,backlog)。其中 backlog 是我们创建 ServerSocket 时指定的参数,最终会传递给 listen 方法: 1int listen(int sockfd, int backlog);如果我们设置的 backlog 大于net.core.somaxconn,accept 队列的长度将被设置为net.core.somaxconn,而这个 backlog 参数就是 Tomcat 中的acceptCount参数,默认值是 100,但请注意net.core.somaxconn的默认值是 128。你可以想象在高并发情况下当 Tomcat 来不及处理新的连接时,这些连接都被堆积在 accept 队列中,而acceptCount参数可以控制 accept 队列的长度,超过这个长度时,内核会向客户端发送 RST,这样客户端会触发上文提到的“Connection reset”异常。 而 Tomcat 中的maxConnections是指 Tomcat 在任意时刻接收和处理的最大连接数。当 Tomcat 接收的连接数达到 maxConnections 时,Acceptor 线程不会再从 accept 队列中取走连接,这时 accept 队列中的连接会越积越多。 maxConnections 的默认值与连接器类型有关:NIO 的默认值是 10000,APR 默认是 8192。 所以你会发现 Tomcat 的最大并发连接数等于maxConnections + acceptCount。如果 acceptCount 设置得过大,请求等待时间会比较长;如果 acceptCount 设置过小,高并发情况下,客户端会立即触发 Connection reset 异常。 Tomcat 网络调优实战接下来我们通过一个直观的例子来加深对上面两个参数的理解。我们先重现流量高峰时 accept 队列堆积的情况,这样会导致客户端触发“Connection reset”异常,然后通过调整参数解决这个问题。主要步骤有: 下载和安装压测工具JMeter。解压后打开,我们需要创建一个测试计划、一个线程组、一个请求和,如下图所示。测试计划:
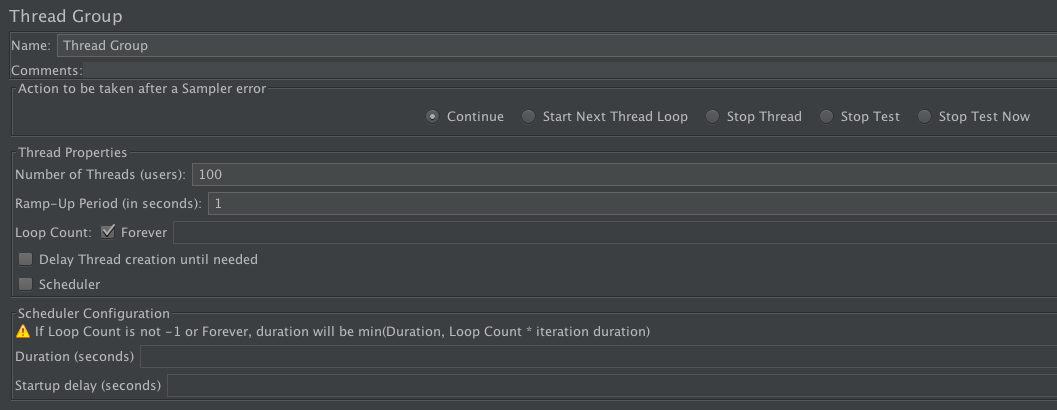
线程组(线程数这里设置为 1000,模拟大流量):
请求(请求的路径是 Tomcat 自带的例子程序):
启动 Tomcat。 开启 JMeter 测试,在 View Results Tree 中会看到大量失败的请求,请求的响应里有“Connection reset”异常,也就是前面提到的,当 accept 队列溢出时,服务端的内核发送了 RST 给客户端,使得客户端抛出了这个异常。
修改内核参数,在/etc/sysctl.conf中增加一行net.core.somaxconn=2048,然后执行命令sysctl -p。 修改 Tomcat 参数 acceptCount 为 2048,重启 Tomcat。
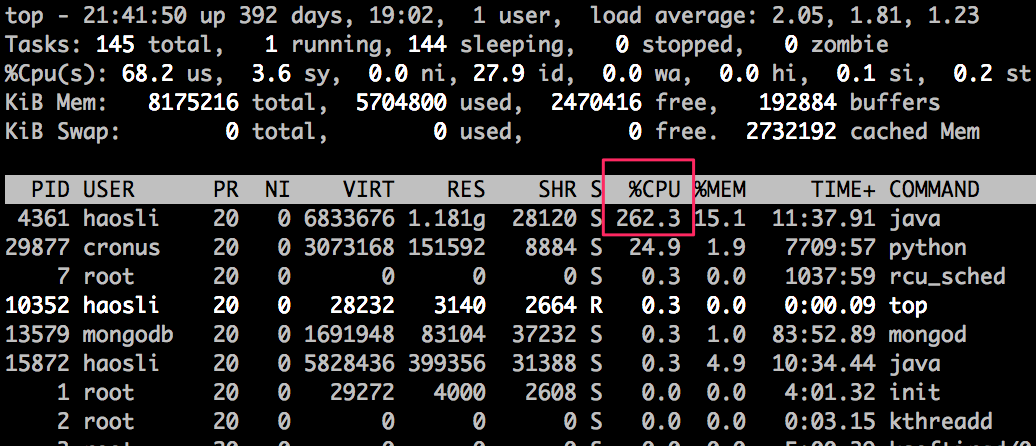
在 Socket 网络通信过程中,我们不可避免地会碰到各种 Java 异常,了解这些异常产生的原因非常关键,通过这些信息我们大概知道问题出在哪里,如果一时找不到问题代码,我们还可以通过网络抓包工具来分析数据包。 在这个基础上,我们还分析了 Tomcat 中两个比较重要的参数:acceptCount 和 maxConnections。acceptCount 用来控制内核的 TCP 连接队列长度,maxConnections 用于控制 Tomcat 层面的最大连接数。在实战环节,我们通过调整 acceptCount 和相关的内核参数somaxconn,增加了系统的并发度。 39 | Tomcat进程占用CPU过高怎么办?在性能优化这个主题里,前面我们聊过了 Tomcat 的内存问题和网络相关的问题,接下来我们看一下 CPU 的问题。CPU 资源经常会成为系统性能的一个瓶颈,这其中的原因是多方面的,可能是内存泄露导致频繁 GC,进而引起 CPU 使用率过高;又可能是代码中的 Bug 创建了大量的线程,导致 CPU 上下文切换开销。 今天我们就来聊聊 Tomcat 进程的 CPU 使用率过高怎么办,以及怎样一步一步找到问题的根因。 “Java 进程 CPU 使用率高”的解决思路是什么?通常我们所说的 CPU 使用率过高,这里面其实隐含着一个用来比较高与低的基准值,比如 JVM 在峰值负载下的平均 CPU 利用率为 40%,如果 CPU 使用率飙到 80% 就可以被认为是不正常的。 典型的 JVM 进程包含多个 Java 线程,其中一些在等待工作,另一些则正在执行任务。在单个 Java 程序的情况下,线程数可以非常低,而对于处理大量并发事务的互联网后台来说,线程数可能会比较高。 对于 CPU 的问题,最重要的是要找到是哪些线程在消耗 CPU,通过线程栈定位到问题代码;如果没有找到个别线程的 CPU 使用率特别高,我们要怀疑到是不是线程上下文切换导致了 CPU 使用率过高。下面我们通过一个实例来学习 CPU 问题定位的过程。 定位高 CPU 使用率的线程和代码 写一个模拟程序来模拟 CPU 使用率过高的问题,这个程序会在线程池中创建 4096 个线程。代码如下: 1234567891011121314151617181920212223242526@SpringBootApplication@EnableSchedulingpublic class DemoApplication { // 创建线程池,其中有 4096 个线程。 private ExecutorService executor = Executors.newFixedThreadPool(4096); // 全局变量,访问它需要加锁。 private int count; // 以固定的速率向线程池中加入任务 @Scheduled(fixedRate = 10) public void lockContention() { IntStream.range(0, 1000000) .forEach(i -> executor.submit(this::incrementSync)); } // 具体任务,就是将 count 数加一 private synchronized void incrementSync() { count = (count + 1) % 10000000; } public static void main(String[] args) { SpringApplication.run(DemoApplication.class, args); } } 在 Linux 环境下启动程序: 1java -Xss256k -jar demo-0.0.1-SNAPSHOT.jar请注意,这里我将线程栈大小指定为 256KB。对于测试程序来说,操作系统默认值 8192KB 过大,因为我们需要创建 4096 个线程。 使用 top 命令,我们看到 Java 进程的 CPU 使用率达到了 262.3%,注意到进程 ID 是 4361。
从图上我们可以看到,有个叫“scheduling-1”的线程占用了较多的 CPU,达到了 42.5%。因此下一步我们要找出这个线程在做什么事情。 为了找出线程在做什么事情,我们需要用 jstack 命令生成线程快照,具体方法是: 1jstack 4361jstack 的输出比较大,你可以将输出写入文件: 1jstack 4361 > 4361.log然后我们打开 4361.log,定位到第 4 步中找到的名为“scheduling-1”的线程,发现它的线程栈如下:
从线程栈中我们看到了AbstractExecutorService.submit这个函数调用,说明它是 Spring Boot 启动的周期性任务线程,向线程池中提交任务,这个线程消耗了大量 CPU。 进一步分析上下文切换开销一般来说,通过上面的过程,我们就能定位到大量消耗 CPU 的线程以及有问题的代码,比如死循环。但是对于这个实例的问题,你是否发现这样一个情况:Java 进程占用的 CPU 是 262.3%, 而“scheduling-1”线程只占用了 42.5% 的 CPU,那还有将近 220% 的 CPU 被谁占用了呢? 不知道你注意到没有,我们在第 4 步用top -H -p 4361命令看到的线程列表中还有许多名为“pool-1-thread-x”的线程,它们单个的 CPU 使用率不高,但是似乎数量比较多。你可能已经猜到,这些就是线程池中干活的线程。那剩下的 220% 的 CPU 是不是被这些线程消耗了呢? 要弄清楚这个问题,我们还需要看 jstack 的输出结果,主要是看这些线程池中的线程是不是真的在干活,还是在“休息”呢?
通过上面的图我们发现这些“pool-1-thread-x”线程基本都处于 WAITING 的状态,那什么是 WAITING 状态呢?或者说 Java 线程都有哪些状态呢?你可以通过下面的图来理解一下:
从图上我们看到“Blocking”和“Waiting”是两个不同的状态,我们要注意它们的区别: Blocking 指的是一个线程因为等待临界区的锁(Lock 或者 synchronized 关键字)而被阻塞的状态,请你注意的是处于这个状态的线程还没有拿到锁。 Waiting 指的是一个线程拿到了锁,但是需要等待其他线程执行某些操作。比如调用了 Object.wait、Thread.join 或者 LockSupport.park 方法时,进入 Waiting 状态。前提是这个线程已经拿到锁了,并且在进入 Waiting 状态前,操作系统层面会自动释放锁,当等待条件满足,外部调用了 Object.notify 或者 LockSupport.unpark 方法,线程会重新竞争锁,成功获得锁后才能进入到 Runnable 状态继续执行。回到我们的“pool-1-thread-x”线程,这些线程都处在“Waiting”状态,从线程栈我们看到,这些线程“等待”在 getTask 方法调用上,线程尝试从线程池的队列中取任务,但是队列为空,所以通过 LockSupport.park 调用进到了“Waiting”状态。那“pool-1-thread-x”线程有多少个呢?通过下面这个命令来统计一下,结果是 4096,正好跟线程池中的线程数相等。
你可能好奇了,那剩下的 220% 的 CPU 到底被谁消耗了呢?分析到这里,我们应该怀疑 CPU 的上下文切换开销了,因为我们看到 Java 进程中的线程数比较多。下面我们通过 vmstat 命令来查看一下操作系统层面的线程上下文切换活动:
如果你还不太熟悉 vmstat,可以在这里学习如何使用 vmstat 和查看结果。其中 cs 那一栏表示线程上下文切换次数,in 表示 CPU 中断次数,我们发现这两个数字非常高,基本证实了我们的猜测,线程上下文切切换消耗了大量 CPU。那么问题来了,具体是哪个进程导致的呢? 我们停止 Spring Boot 测试程序,再次运行 vmstat 命令,会看到 in 和 cs 都大幅下降了,这样就证实了引起线程上下文切换开销的 Java 进程正是 4361。
当我们遇到 CPU 过高的问题时,首先要定位是哪个进程的导致的,之后可以通过top -H -p pid命令定位到具体的线程。其次还要通 jstack 查看线程的状态,看看线程的个数或者线程的状态,如果线程数过多,可以怀疑是线程上下文切换的开销,我们可以通过 vmstat 和 pidstat 这两个工具进行确认。 40 | 谈谈Jetty性能调优的思路关于 Tomcat 的性能调优,前面我主要谈了工作经常会遇到的有关 JVM GC、监控、I/O 和线程池以及 CPU 的问题定位和调优,今天我们来看看 Jetty 有哪些调优的思路。 关于 Jetty 的性能调优,官网上给出了一些很好的建议,分为操作系统层面和 Jetty 本身的调优,我们将分别来看一看它们具体是怎么做的,最后再通过一个实战案例来学习一下如何确定 Jetty 的最佳线程数。 操作系统层面调优对于 Linux 操作系统调优来说,我们需要加大一些默认的限制值,这些参数主要可以在/etc/security/limits.conf中或通过sysctl命令进行配置,其实这些配置对于 Tomcat 来说也是适用的,下面我来详细介绍一下这些参数。 TCP 缓冲区大小 TCP 的发送和接收缓冲区最好加大到 16MB,可以通过下面的命令配置: 1234sysctl -w net.core.rmem_max = 16777216sysctl -w net.core.wmem_max = 16777216sysctl -w net.ipv4.tcp_rmem =“4096 87380 16777216”sysctl -w net.ipv4.tcp_wmem =“4096 16384 16777216”TCP 队列大小 net.core.somaxconn控制 TCP 连接队列的大小,默认值为 128,在高并发情况下明显不够用,会出现拒绝连接的错误。但是这个值也不能调得过高,因为过多积压的 TCP 连接会消耗服务端的资源,并且会造成请求处理的延迟,给用户带来不好的体验。因此我建议适当调大,推荐设置为 4096。 1sysctl -w net.core.somaxconn = 4096net.core.netdev_max_backlog用来控制 Java 程序传入数据包队列的大小,可以适当调大。 123sysctl -w net.core.netdev_max_backlog = 16384sysctl -w net.ipv4.tcp_max_syn_backlog = 8192sysctl -w net.ipv4.tcp_syncookies = 1端口 如果 Web 应用程序作为客户端向远程服务器建立了很多 TCP 连接,可能会出现 TCP 端口不足的情况。因此最好增加使用的端口范围,并允许在 TIME_WAIT 中重用套接字: 12sysctl -w net.ipv4.ip_local_port_range =“1024 65535”sysctl -w net.ipv4.tcp_tw_recycle = 1文件句柄数 高负载服务器的文件句柄数很容易耗尽,这是因为系统默认值通常比较低,我们可以在/etc/security/limits.conf中为特定用户增加文件句柄数: 12用户名 hard nofile 40000用户名 soft nofile 40000拥塞控制 Linux 内核支持可插拔的拥塞控制算法,如果要获取内核可用的拥塞控制算法列表,可以通过下面的命令: 1sysctl net.ipv4.tcp_available_congestion_control这里我推荐将拥塞控制算法设置为 cubic: 1sysctl -w net.ipv4.tcp_congestion_control = cubic Jetty 本身的调优Jetty 本身的调优,主要是设置不同类型的线程的数量,包括 Acceptor 和 Thread Pool。 Acceptors Acceptor 的个数 accepts 应该设置为大于等于 1,并且小于等于 CPU 核数。 Thread Pool 限制 Jetty 的任务队列非常重要。默认情况下,队列是无限的!因此,如果在高负载下超过 Web 应用的处理能力,Jetty 将在队列上积压大量待处理的请求。并且即使负载高峰过去了,Jetty 也不能正常响应新的请求,这是因为仍然有很多请求在队列等着被处理。 因此对于一个高可靠性的系统,我们应该通过使用有界队列立即拒绝过多的请求(也叫快速失败)。那队列的长度设置成多大呢,应该根据 Web 应用的处理速度而定。比如,如果 Web 应用每秒可以处理 100 个请求,当负载高峰到来,我们允许一个请求可以在队列积压 60 秒,那么我们就可以把队列长度设置为 60 × 100 = 6000。如果设置得太低,Jetty 将很快拒绝请求,无法处理正常的高峰负载,以下是配置示例: 123456789101112131415 6000 10 200 false那如何配置 Jetty 的线程池中的线程数呢?跟 Tomcat 一样,你可以根据实际压测,如果 I/O 越密集,线程阻塞越严重,那么线程数就可以配置多一些。通常情况,增加线程数需要更多的内存,因此内存的最大值也要跟着调整,所以一般来说,Jetty 的最大线程数应该在 50 到 500 之间。 Jetty 性能测试接下来我们通过一个实验来测试一下 Jetty 的性能。我们可以在这里下载 Jetty 的 JAR 包。
第二步我们创建一个 Handler,这个 Handler 用来向客户端返回“Hello World”,并实现一个 main 方法,根据传入的参数创建相应数量的线程池。 1234567891011121314151617181920212223242526272829public class HelloWorld extends AbstractHandler { @Override public void handle(String target, Request baseRequest, HttpServletRequest request, HttpServletResponse response) throws IOException, ServletException { response.setContentType("text/html; "); response.setStatus(HttpServletResponse.SC_OK); response.getWriter().println("Hello World"); baseRequest.setHandled(true); } public static void main(String[] args) throws Exception { // 根据传入的参数控制线程池中最大线程数的大小 int maxThreads = Integer.parseInt(args[0]); System.out.println("maxThreads:" + maxThreads); // 创建线程池 QueuedThreadPool threadPool = new QueuedThreadPool(); threadPool.setMaxThreads(maxThreads); Server server = new Server(threadPool); ServerConnector http = new ServerConnector(server, new HttpConnectionFactory(new HttpConfiguration())); http.setPort(8000); server.addConnector(http); server.start(); server.join(); }}第三步,我们编译这个 Handler,得到 HelloWorld.class。 1javac -cp jetty.jar HelloWorld.java第四步,启动 Jetty server,并且指定最大线程数为 4。 1java -cp .:jetty.jar HelloWorld 4第五步,启动压测工具 Apache Bench。关于 Apache Bench 的使用,你可以参考这里。 1ab -n 200000 -c 100 http://localhost:8000/上面命令的意思是向 Jetty server 发出 20 万个请求,开启 100 个线程同时发送。 经过多次压测,测试结果稳定以后,在 Linux 4 核机器上得到的结果是这样的:
从上面的测试结果我们可以看到,20 万个请求在 9.99 秒内处理完成,RPS 达到了 20020。 不知道你是否好奇,为什么我把最大线程数设置为 4 呢?是不是有点小? 别着急,接下来我们就试着逐步加大最大线程数,直到找到最佳值。下面这个表格显示了在其他条件不变的情况下,只调整线程数对 RPS 的影响。
我们发现一个有意思的现象,线程数从 4 增加到 6,RPS 确实增加了。但是线程数从 6 开始继续增加,RPS 不但没有跟着上升,反而下降了,而且线程数越多,RPS 越低。 发生这个现象的原因是,测试机器的 CPU 只有 4 核,而我们测试的程序做得事情比较简单,没有 I/O 阻塞,属于 CPU 密集型程序。对于这种程序,最大线程数可以设置为比 CPU 核心稍微大一点点。那具体设置成多少是最佳值呢,我们需要根据实验里的步骤反复测试。你可以看到在我们这个实验中,当最大线程数为 6,也就 CPU 核数的 1.5 倍时,性能达到最佳。 本期精华今天我们首先学习了 Jetty 调优的基本思路,主要分为操作系统级别的调优和 Jetty 本身的调优,其中操作系统级别也适用于 Tomcat。接着我们通过一个实例来寻找 Jetty 的最佳线程数,在测试中我们发现,对于 CPU 密集型应用,将最大线程数设置 CPU 核数的 1.5 倍是最佳的。因此,在我们的实际工作中,切勿将线程池直接设置得很大,因为程序所需要的线程数可能会比我们想象的要小。 41 | 热点问题答疑(4): Tomcat和Jetty有哪些不同?作为专栏最后一个模块的答疑文章,我想是时候总结一下 Tomcat 和 Jetty 的区别了。专栏里也有同学给我留言,询问有关 Tomcat 和 Jetty 在系统选型时需要考虑的地方,今天我也会通过一个实战案例来比较一下 Tomcat 和 Jetty 在实际场景下的表现,帮你在做选型时有更深的理解。 我先来概括一下 Tomcat 和 Jetty 两者最大的区别。大体来说,Tomcat 的核心竞争力是成熟稳定,因为它经过了多年的市场考验,应用也相当广泛,对于比较复杂的企业级应用支持得更加全面。也因为如此,Tomcat 在整体结构上比 Jetty 更加复杂,功能扩展方面可能不如 Jetty 那么方便。 而 Jetty 比较年轻,设计上更加简洁小巧,配置也比较简单,功能也支持方便地扩展和裁剪,比如我们可以把 Jetty 的 SessionHandler 去掉,以节省内存资源,因此 Jetty 还可以运行在小型的嵌入式设备中,比如手机和机顶盒。当然,我们也可以自己开发一个 Handler,加入 Handler 链中用来扩展 Jetty 的功能。值得一提的是,Hadoop 和 Solr 都嵌入了 Jetty 作为 Web 服务器。 从设计的角度来看,Tomcat 的架构基于一种多级容器的模式,这些容器组件具有父子关系,所有组件依附于这个骨架,而且这个骨架是不变的,我们在扩展 Tomcat 的功能时也需要基于这个骨架,因此 Tomcat 在设计上相对来说比较复杂。当然 Tomcat 也提供了较好的扩展机制,比如我们可以自定义一个 Valve,但相对来说学习成本还是比较大的。而 Jetty 采用 Handler 责任链模式。由于 Handler 之间的关系比较松散,Jetty 提供 HandlerCollection 可以帮助开发者方便地构建一个 Handler 链,同时也提供了 ScopeHandler 帮助开发者控制 Handler 链的访问顺序。关于这部分内容,你可以回忆一下专栏里讲的回溯方式的责任链模式。 说了一堆理论,你可能觉得还是有点抽象,接下来我们通过一个实例,来压测一下 Tomcat 和 Jetty,看看在同等流量压力下,Tomcat 和 Jetty 分别表现如何。需要说明的是,通常我们从吞吐量、延迟和错误率这三个方面来比较结果。 测试的计划是这样的,我们还是用专栏第 36 期中的 Spring Boot 应用程序。首先用 Spring Boot 默认的 Tomcat 作为内嵌式 Web 容器,经过一轮压测后,将内嵌式的 Web 容器换成 Jetty,再做一轮测试,然后比较结果。为了方便观察各种指标,我在本地开发机器上做这个实验。 我们会在每个请求的处理过程中休眠 1 秒,适当地模拟 Web 应用的 I/O 等待时间。JMeter 客户端的线程数为 100,压测持续 10 分钟。在 JMeter 中创建一个 Summary Report,在这个页面上,可以看到各种统计指标。
第一步,压测 Tomcat。启动 Spring Boot 程序和 JMeter,持续 10 分钟,以下是测试结果,结果分为两部分: 吞吐量、延迟和错误率
资源使用情况
第二步,我们将 Spring Boot 的 Web 容器替换成 Jetty,具体步骤是在 pom.xml 文件中的 spring-boot-starter-web 依赖修改下面这样: 1234567891011121314 org.springframework.boot spring-boot-starter-web org.springframework.boot spring-boot-starter-tomcat org.springframework.boot spring-boot-starter-jetty编译打包,启动 Spring Boot,再启动 JMeter 压测,以下是测试结果: 吞吐量、延迟和错误率
资源使用情况
下面我们通过一个表格来对比 Tomcat 和 Jetty:
从表格中的数据我们可以看到: Jetty 在吞吐量和响应速度方面稍有优势,并且 Jetty 消耗的线程和内存资源明显比 Tomcat 要少,这也恰好说明了 Jetty 在设计上更加小巧和轻量级的特点。 但是 Jetty 有 2.45% 的错误率,而 Tomcat 没有任何错误,并且我经过多次测试都是这个结果。因此我们可以认为 Tomcat 比 Jetty 更加成熟和稳定。当然由于测试场景的限制,以上数据并不能完全反映 Tomcat 和 Jetty 的真实能力。但是它可以在我们做选型的时候提供一些参考:如果系统的目标是资源消耗尽量少,并且对稳定性要求没有那么高,可以选择轻量级的 Jetty;如果你的系统是比较关键的企业级应用,建议还是选择 Tomcat 比较稳妥。 最后用一句话总结 Tomcat 和 Jetty 的区别:Tomcat 好比是一位工作多年比较成熟的工程师,轻易不会出错、不会掉链子,但是他有自己的想法,不会轻易做出改变。而 Jetty 更像是一位年轻的后起之秀,脑子转得很快,可塑性也很强,但有时候也会犯一点小错误。 |













































【本文地址】
今日新闻 |
推荐新闻 |